How well does ChatGPT speak Japanese?
blog japanese machine learningUpdate June 16: I uploaded the code I used to get the results in the latter half of this post to github.
Large language models, like the ones that power ChatGPT, have triggered a lot of excitement in the machine learning and natural language processing communities in the past few years. Though the most advanced LLMs are usually developed with a focus on English, many can also understand and output Japanese.
In this post I’d like to take a technical look at how these state-of-the-art models work with Japanese, and how good they are at it. This is an important question for Japanese companies: they are behind in the LLM race and need to decide if they should build their own Japanese-focused competitors to the cutting-edge English models.
I’ll focus on the Japanese capabilities of Open AI’s GPT family of models. These are the largest and most capable LLMs in production. The latest model, GPT-4, was announced in March 2023, while the older GPT-3 model powers the free tier of ChatGPT. While GPT-4 can also accept images as input, in this post I’ll just focus on the text side of the models.
Tokenization
The first step taken by any LLM is to split input text into pieces, or tokens, that the model will at the next step convert to vectors that it can perform mathematical operations on. There are many different ways to tokenize text, but schematically each token represents a word or a piece of a word. Later, a model outputs text by spitting out one token at a time. Since tokenization is key to a model’s input and output, understanding how text in different languages is tokenized is important to understanding how a model will perform in those languages.
GPT models are able to take in Japanese text because they use a very flexible tokenizer, tiktoken. OpenAI has open-sourced tiktoken, so we can carefully study how it works for Japanese.
tiktoken is a Byte Pair Encoder. Byte pair encoders take in text as a stream of bytes, which in tiktoken’s case represent the UTF-8 encoding of Unicode characters. For example the byte 01100001 represents the character ‘a’. Because one byte can only have different values and Unicode includes more than a million different characters, most non-Latin characters are represented by more than one byte. For example the first Hiragana character ‘あ’ is represented in UTF-8 by the three-byte sequence 11100011 10000001 10000010.
Byte pair encoders then compress the byte stream by replacing the most commonly appearing consecutive pair of bytes with a single symbol. ‘Most commonly appearing’ means over some reference dataset, which in GPT’s case is probably something like a large sample of the internet. Once the most commonly appearing pair of bytes has been replaced, the byte pair encoder now has a vocabulary of 257 tokens: 256 bytes plus the one new symbol which represents the most common pair.
The byte pair encoder then repeats the process, merging the next most common pair of tokens into a new one, continuing until the vocabulary reaches some chosen size. For GPT-4 and the latest GPT-3 variants, this is roughly 100,000 tokens.
Byte pair encoding can be viewed as a lossless compression algorithm. At the expense of writing down a large vocabulary list that tells you how to map between tokens and byte sequences, you can replace frequently occurring sequences in your data with a single token.
Let’s look at some tiktoken encodings.
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4")
enc.encode("dog")
# => [18964]We see that the word ‘dog’, which would take 3 bytes to represent, is represented by the single token 18964. ‘dog’ must have been a frequently appearing sequence in the byte pair encoder’s reference dataset.
Now let’s look at what happens in Japanese.
enc.encode("犬") # 'dog' in Japanese
# => [163, 232, 105]Unlike in English, the single Japanese character for ‘dog’ takes three tokens to represent. These three tokens point directly to the three bytes that make up the character in UTF-8. The dataset that OpenAI used to make the byte-pair encoding for GPT-4 must have been dominated by English text so that common Japanese byte sequences like the ones in ‘犬’ were not optimized.
This biased tokenization compounds for longer texts. Let’s compare the tokenization of the Pater Noster in English and Japanese. This is a convenient text because, thanks to the tireless work of Christian missionaries, semantically equivalent versions exist for almost every language on Earth.
with open("pater.json") as fp:
# pater.json is available from gist.github.com/passaglia
pater = json.load(fp)
len(enc.encode(pater["English"]["English (Early Modern English Dated 1559)"]))
# ==> 68
len(enc.encode(pater["Japanese"]["日本語 (カトリック(2))"]))
# ==> 142It takes GPT models more than twice as many tokens to represent the Japanese version of the Pater Noster than the English version, despite them having the same information content. This points to a major obstacle for the Japanese performance of GPT: the model has to put in twice as much more work to read and output Japanese text than it does for English.
Poor tokenization is not unique to Japanese. All non-English languages suffer from it to some extent. We can confirm this by looking at the Pater Noster in other languages.
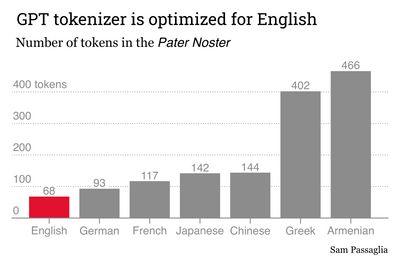
Languages like Greek and Armenian get especially screwed, requiring respectively 6 and 7 times more tokens than English to represent a semantically equivalent text.
Of course it’s not necessarily beneficial to represent text in as few tokens as possible. Tokenizers usually try to keep semantically distinct elements of a text from being merged, to help the model learn semantically relevant patterns from the data. tiktoken has rules to keep different English words separate so that very common word pairs like ‘I am’ are not merged into one token. None of these kinds of optimizations exist for Japanese.
Poor tokenization for non-English languages like Japanese likely affects the downstream performance of GPT on non-English tasks, and moreover since OpenAI charges for use of its models by the token, using GPT models in Japanese or Greek is many times more expensive than in English.
But before jumping into measurements of model performance let’s look at the rest of the GPT architecture.
Architecture and Training
This section is necessarily speculative: no significant information has been released about the architecture or training of GPT-4, and both GPT-4 and GPT-3 are closed-source. Nonetheless there is some information in their announcement papers, and we can make educated guesses about their architectures and training from the earlier open-source GPT-2 and GPT-1 models.
All GPT models are transformer models. The main difference between them is a steadily increasing model size and a growing and improving set of training data. OpenAI’s most significant innovations have been in the computing infrastructure required to train and deploy larger and larger models rather than in the architecture of the models themselves.
These transformer models are language agnostic: tokens are treated the same way no matter whether they are originally English or Japanese words. They are first embedded in a high-dimensional vector space, with the matrix that maps tokens to vectors itself a trainable part of the model. A sequence of embedded tokens is then processed through a series of attention blocks, repeatedly outputting and sending to the next block a processed embedding of each token. At the final layer the processed embedding of the last token in the input sequence is projected back onto the embedding matrix to generate an output token. In this way transformer models generate new text token by token at the end of an input sequence. For visualizations of this process, see Jay Alammar’s wonderful blog.
The model trains on a huge amount of data, always trying to predict the next token in an observed sequence of text in the data. The strength of the model depends on the amount and quality of text it is trained on.
And while the model architecture itself is language agnostic, the training data certainly is not. GPT-1 and GPT-2 trained only on English-language text and therefore could only speak English. GPT-3’s training data was 92% English and only 0.2% Japanese. No information is available about the training data used for GPT-4.
After the initial bulk training, some versions of GPT-4 and GPT-3 are fine-tuned with Reinforcement Learning from Human Feedback (RLHF). OpenAI has put considerable effort into developing RLHF techniques, which involve tuning the model to produce outputs that human evaluators judge as being desirable. The human evaluators encourage the model to follow instructions closely and to reject inappropriate requests.
OpenAI has not disclosed whether its human feedback pipeline for GPT-4 operates in languages other than English. For GPT-3, the RLHF pipeline was overwhelmingly focused on English language instructions and outputs.
Because of these training imbalances, as well as the aforementioned tokenization bias, the performance of GPT models in Japanese is not guaranteed to be as good as in English. We have to test it empirically.
Performance
Qualitatively, GPT-3 and GPT-4 perform very well in Japanese. GPT-4 can understand Japanese instructions and answer back in Japanese fluently and naturally, and it rejects inappropriate requests just as it does in English. All around it appears to perform about as well in Japanese as in English, though it is about twice as slow in Japanese due to the suboptimal tokenization.
Accordingly, the GPT-4 announcement paper spends a significant amount of time touting the model’s multilingual performance. To back this up quantitatively, OpenAI measures GPT-4’s accuracy on the MMLU benchmark, which is a set of 57 multiple choice exams on subjects like ‘High School US History’ or ‘College Medicine’. The MMLU benchmark is in English, so to test GPT-4’s performance in other languages they first machine-translate the benchmark to other languages using Azure Translate. The performance results reported by OpenAI are as follows (emphasis added):
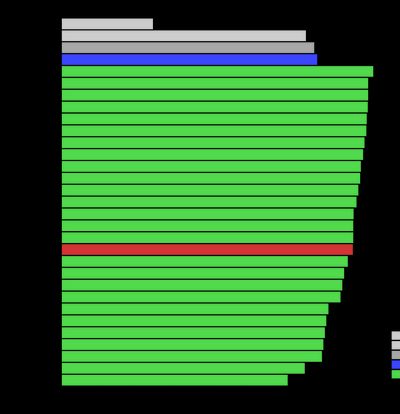
We see that GPT-4’s performance differs from language to language, and roughly speaking GPT-4 performs worse in languages that are more distant from English. Japanese reaches 79.9% accuracy, significantly lower than English’s 85.5% accuracy, and also slightly worse than Greek’s 81.4% accuracy despite Greek’s highly inefficient tokenization.
However, testing multilingual performance on a benchmark machine-translated from English leaves something to be desired. We would like to test GPT-4 on a truly Japanese benchmark and then compare its performance to LLMs developed with a focus on Japanese.
To do so we can look at the Japanese General Language Understanding Evaluation (JGLUE) benchmark. JGLUE is a series of tasks built from the ground up in Japanese to measure natural language understanding.
The most difficult task in the JGLUE benchmark is the Japanese Commonsense Question Answering (JCQA) task, which is a series of ~1000 multiple choice questions testing common-sense. Humans achieve 98.6% accuracy on these questions, and the best-ranked open-source model reaches 90.7% accuracy. Here is one of the more difficult questions from JCQA (translations added):
女性が言われると嬉しくなる形容詞言葉は?
# An i-adjective that women are happy to be called?
0. 開く # open (verb)
1. 黄色い # yellow (i-adjective)
2. キレイ # pretty (ends in i but is not an i-adjective) # gpt-3's choice
3. 美しい # beautiful (i-adjective) #gpt-4's choice
4. 優しい # kind (i-adjective)
Answer: 3. 美しい # beautifuli-adjectives are a class of adjectives in Japanese which in their uninflected form always end in i – but not all uninflected adjectives that end in i are i-adjectives. This question therefore tests some form of uniquely Japanese knowledge that would probably get lost if we machine translated the question to English.
GPT-3 gets the question wrong, mistaking the na-adjective ‘pretty’ for an i-adjective. This a common mistake among Japanese language learners. GPT-4 gets it right, choosing the i-adjective ‘beautiful’.
Note that the i-adjective ‘kind’ is also an option, but both GPT-4 and the answer key assume women would prefer to be called beautiful than kind, reflecting the kind of bias that may be built-in to a lot of datasets and models. These kinds of ambiguities likely explain why humans do not get a perfect score on the exam and put a ceiling on the usefulness of JCQA as a benchmark.
Nonetheless here is an overall performance measurement on JCQA, comparing GPT-3 and GPT-4 both to human performance and to leading Japanese LLMs.
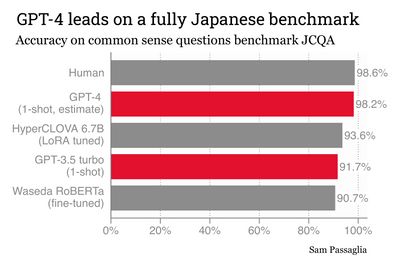
GPT-4 is the best-performing model, greatly surpassing GPT-3’s performance and reaching essentially human-level accuracy on the benchmark. The leading open source model as of April 2023 is the RoBERTa model by Waseda University, which the closed-source HyperCLOVA model developed by LINE has surpassed.
A couple caveats are in order here though: since GPT-4 API access is not yet widely available, I estimated GPT-4’s accuracy by inputting the questions GPT-3 got wrong into the ChatGPT web interface for GPT-4. The accuracy reported in the figure then assumes that GPT-4 would not get any questions wrong that GPT-3 got right. It is therefore an upper bound on the GPT-4 accuracy, which can be confirmed once the GPT-4 API opens up.
A more difficult to estimate issue is contamination: GPT-4 is trained on basically the entire internet, and it’s possible that this includes training on the JCQA benchmark itself. The team behind JGLUE have kept part of the benchmark private, as a test set, and evaluating GPT-4 on this subset would allow a truly unbiased measure of GPT-4’s abilities.
To understand where GPT-4 still has weaknesses, let’s look at a JCQA question that GPT-4 gets wrong.
船舶を安定させる物と同じ発音なのは、どれでしょう?
# Which of these is pronounced in the same way
# as the object used to stabilize a boat?
0. 碇 # anchor (pronounced ikari) # gpt-4 choice
1. 怒り # anger (pronounced ikari or okori)
2. 酒 # alcohol (pronounced sake)
3. 興奮 # excitement (pronounced koufun)
4. 伊刈 # a place name (pronounced ikari)
Answer: 1. 怒り # angerThis question is about word pronunciation, which is not directly encoded in the Japanese writing system. GPT-4 picks option 0, anchor, which is an object used to stabilize a boat. The answer key prefers option 1, anger, because in Japanese anger can be pronounced in the same way as anchor (disregarding pitch accent). GPT-4’s answer could be considered correct, but replacing option 0 with an unrelated term still does not lead GPT-4 to consistently pick option 1.
Option 4, 伊刈, is an area in Saitama which is also pronounced in the same way as anchor and anger, and therefore could also be a correct answer. This might be confusing the model, but GPT-4 still gets the question wrong if both options 0 and 4 are replaced with unrelated words.
So GPT-4 may have a relatively weak understanding of Japanese word pronunciation. It would be useful to test it on a pronunciation annotated corpus, including words where the pronunciation depends on sentence context, the same task I built yomikata to address. From preliminary tests, it seems GPT-4 is very powerful but still not perfect at the pronunciation prediction task.
Conclusion
GPT-4 is the best large language model for Japanese. Despite Japanese being no more than an afterthought during tokenization and training, GPT-4 has qualitatively similar capabilities in Japanese as it does in English.
But because of the poor tokenization, using GPT-4 for Japanese tasks is about twice as slow and twice as expensive as it is in English, and quantitatively GPT-4 does not reach the same performance heights in Japanese as it does in English. If OpenAI is interested in equity across languages, then as a first step it should adjust its per-token pricing strategy to charge less for the tokens used by less-optimized languages.
In the long-term, Japan needs to develop its own LLMs to avoid reliance on the benevolence of foreign companies. LINE’s HyperCLOVA model is promising, but still far behind the state of the art.
The ideal LLM for Japanese won’t be one that just trains on Japanese text. OpenAI’s results show that training on a linguistically varied corpus improves performance across all languages. Rather, a model that treats Japanese fairly will be one that tokenizes text in a linguistically equitable way and which ensures that linguistic diversity is prioritized throughout the training process.
If large language models and their developers don’t value the variety and richness of human languages as they appear on Earth, they will find themselves just perpetuating linguistic injustice and extinction.