Ranking Japanese LLMs with Rakuda
blog japanese machine learning yuzu-aiThis post also appears on the YuzuAI blog, and all of the code and data used to get these results is available on github.
The open-source community has been hard at work trying to catch up to closed Large Language Models like ChatGPT. Open models — models whose insides are released publicly — are important because they enable AI research and development outside of the control of large corporations.
In English, the best open models are now at roughly the level of the GPT-3.5 model that powers the free tier of ChatGPT. The Japanese performance of open models seems to lag behind, however, and the Japanese open-source community is not as active as the community in the West. Nonetheless the past couple months have seen the release of a 3.6-billion parameter model by rinna and the 7-billion parameter open-calm model by CyberAgent, both trained exclusively on Japanese text.
How good are open-source models in Japanese, and how do they compare to the strong Japanese performance of ChatGPT? And within the open-source space, how do large models trained primarily in English compare to models which are smaller but which focus their training and tokenization architectures on Japanese?
To answer these questions, we introduce here the Rakuda benchmark and ranking for Japanese AI assistants. Read on for details about how it works, or head directly to the leaderboard to see how the first 6 competitors stack up!
The Rakuda Benchmark
One powerful way to test an LLM is to ask it questions to which you know the answer. This is the approach taken by many popular benchmarks like the Japanese General Language Understanding Evaluation (JGLUE). In order to measure a model’s performance on these questions unambiguously, these benchmarks are often designed as multiple choice tests. For a ranking of models on JGLUE, see this StabilityAI fork of EleutherAI’s lm-evaluation-harness.
But LLMs are capable of much more than answering multiple choice questions. ChatGPT and similar models can write detailed, reasoned, and pertinent responses to open-ended questions. The performance of these AI assistants is defined not by a clear-cut right-or-wrong benchmark but by how useful they are to their users, and we would like to measure that usefulness.
One way to measure usefulness is to simply ask users directly. This is the approach taken by LMSYS’s Chatbot Arena. They provide a web interface where users can input questions, just like they would to ChatGPT, and LMSYS serves them back answers generated by two different AI assistants. The user is asked to decide which answer is better, and based on users’ preferences LMSYS creates an LLM leaderboard.
We’ll talk more about just how to create such a ranking down below, but in the meantime it’s important to understand that this approach is in some ways very easy, because you don’t need to come up with a list of questions and answers yourself, and in other ways hard, because you have to serve models reliably and quickly to users on-demand.
A simpler approach is to come up with a list of questions yourself. Since the question list is fixed, you can generate all the answers at once and you don’t have to serve any models to users over the internet. You still don’t need to specify answers to the questions, because you can still just compare models’ responses against each other rather than against some ground truth. The questions can be open-ended and admit a wide range of possible answers, and they can be designed to test exactly the skills you’re interesting in.
Benchmarks and rankings based on open-ended question lists have proven incredibly useful in stimulating open-source development. Benchmarks based on the Vicuna list are used in many papers, and Huggingface uses a similar list to produce its LLM assistant leaderboard. But so far there has been no such benchmark for Japanese.
That’s why we designed Rakuda, the first question set designed to evaluate how well AI Assistants can answer Japanese-specific questions. We’re releasing it to the public as a dataset on Huggingface.
Rakuda contains 40 questions in Japanese about Japanese history, society, government, and geography, and most questions admit a wide range of possible answers. Here’s an example question from each category
## Rakuda questions
歴史: 幕末に西洋と接触した結果、日本で生じた社会変革について説明してください。
# History: Explain the societal transformations that occurred in Japan
# as a result of contact with the West during the Bakumatsu.
社会: 日本の労働市場の女性活躍推進に関する政策とその結果について説明してください。
# Society: Explain the policies that have been implemented to promote
# the success of women in the Japanese workplace,
# and those policies' results.
政治: 日本の議院内閣制度を説明し、そのメリットとデメリットを詳述してください。
# Government: Explain Japan's parliamentary system of government,
# and its merits and demerits.
地理: 熊野古道は、日本のどの地方に位置し、主に何のために使われていましたか。
# Geography: Where is the Kumano Kodō,
# and what was it primarily used for?We got these by asking ChatGPT-4 to generate useful questions to evaluate Japanese high-school students. We kept the ChatGPT-4 outputs we liked, removed questions we thought were bad, and lightly edited some for clarity.
Evaluating and Ranking Models on Rakuda
Rakuda does not contain an answer key. Models are evaluated by generating answers to the questions and then comparing their answers against each other.
Ideally we would get humans reviewers to do these comparisons, looking at two models’ outputs to the same question and deciding which answer is better. But doing all pairwise combinations for 6 LLMs on 40 questions would take 6x5x40 = 1200 reviews (we want to compare outputs in both A-B and B-A orderings to eliminate any primacy bias of the reviewers). That’s a lot of work for a human, so instead we ask the best LLM we have access to, GPT-3.5, to do the reviewing. We can do this because a recent paper showed that GPT-3.5 agrees with human reviewers 83% of the time. GPT-4 does even better, so please contact us if you have API access to GPT-4 and would be willing to help us improve our benchmark.
We send GPT-3.5 a question from the Rakuda list and ask it to choose which of two answers is better. We also allow it to choose a draw, but it doesn’t do so very often. We do this for all possible model match-ups for every question and end up with a long table that looks like
model_1 | model_2 | winner
------------------------------
gpt-3 | open-calm | 1
rinna-3.6b | gpt-3 | 2
rinna-3.6b | open-calm | 2
..
(1200 rows)To turn this list of pairwise results into a model ranking, perhaps the simplest thing we could do is to rank models based on their win rate across all matches. If all models play the same number of matches against the same opponents, then their win rate is probably the closest thing to their ‘true’ strengths.
But we would also like to be able to compute a ranking when these conditions are violated. Since computing all pairwise combinations for models requires matches, computing every pairwise combination will rapidly become intractable. Moreover as we add new models to our ranking, we would like to estimate their strength before they’ve played every other model many times. To do that we need a mathematical model that can predict the outcome of a match between opponents that have never played each other.
The Bradley-Terry model is one way to do that. It models one-on-one competitions by assigning to every competitor (in our case a Japanese LLM) a strength parameter . It then assumes that the probability that competitor beats competitor in a match just depends on their relative strength . A commonly used form for that probability is
,
where we have complicated things a bit by adding a home-field advantage parameter that enhances model 's strength. In this context the home-field advantage is any bias the reviewer might have towards or against the model that is shown to it first. We always order match pairs with as the home team.
We now want to fit for the vector of model strengths given our data. We can define the data vector as a vector that contains an entry for each match: 1 if the home team wins or 0 if the home team loses. Then the probability of getting our exact data vector given a set of model parameters is just the product over every match of if the home team won the match, or if the home team lost. This is the likelihood
The best fit parameters are those which maximize the likelihood. This maximization is very easy to do in python with scipy’s optimize library. A couple technical points: first, we deal with draws by counting them as a half-win for each team. Second, because winning probabilities are controlled only by relative model strengths, a constant can be added or subtracted to all model strengths without changing the likelihood. We fix this gauge freedom by imposing that the model strengths all add up to zero.
Once we have the best-fit model strengths, we would like to know their uncertainties. In our Bayesian framework, the uncertainties are related to the shape of the posterior probability distribution of the parameters, which is proportional to the likelihood times the prior probability of the parameters. There are many ways to estimate the posterior probability distribution, but the one that requires the least amount of brain power is certainly Markov chain Monte Carlo.
MCMC is an easy way to sample from high-dimensional distributions, and in Bayesian statistics it is used to sample from the posterior distribution. How far the samples stray from the best-fit points tells us the parameter uncertainties. MCMC is very straightforward to implement using the emcee package. See Hogg et al for a primer on Bayesian analysis.
Before we go on to the results, first a note about Elo scores. Elo scores are another commonly used way to rank the relative skill of players in zero-sum competitions. In fact, they are based on the same underlying Bradley-Terry model we use here. The difference lies in how the player strengths are actually estimated from the data. In the Elo system, scores are gradually updated match-by-match based on the match result and the pre-match Elo scores of the competitors. This is popular with players because they can easily calculate the exact impact a win or loss will have on their score. But from a parameter estimation standpoint it is sub-optimal and will only slowly approach the maximum likelihood values. If you have access to a computer, better to take the Bayesian approach and fit all strengths based on all matches all at once, as we’ve done here.
The Rakuda Leaderboard
For our initial release we run our benchmark with 6 models. These are:
- GPT-3.5 (OpenAI): This is the best model in the ranking and also the model we use as a reviewer. We might worry that as a reviewer GPT-3.5 is biased towards its own answers, but GPT-3.5 is so unambiguously better than other models that such biases are not a major concern.
- open-calm-7b (CyberAgent) and stormy-7b-10ep (Izumi-Lab): open-calm is a 7-billion parameter base model trained by CyberAgent on a Japanese corpus. stormy-7b-10ep is a version of open-calm fine-tuned on a large set of question-answer pairs by University of Tokyo researchers. To try to induce open-calm-7b to give helpful answers, we prompt it to be an assistant.
- japanese-gpt-neox-3.6b, japanese-gpt-neox-3.6b-sft-v2, and japanese-gpt-neox-3.6b-ppo (rinna): These models are trained by the rinna corporation and for conciseness we will refer to them as rinna-3.6b, rinna-3.6b-sft, and rinna-3.6b-ppo. rinna-3.6b is the base model, while rinna-3.6b-sft is instruction fine-tuned. rinna-3.6-ppo is further trained with proximal policy optimization, a reinforcement learning technique. Again we prompt the base model to try to get it to assist the user.
We get each of these models to answer all the Rakuda questions and then ask GPT-3.5 to judge all the answers against each other. These answers and reviews are all in the github repository. We find the following win rates for each model:
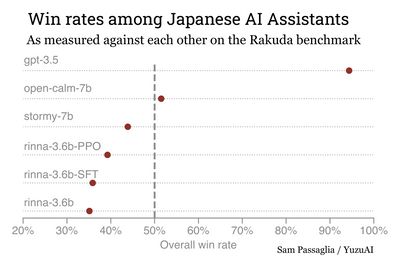
We then use MCMC to estimate the Bradley-Terry parameters and their uncertainties. See this notebook for the calculation. We find the following strengths:
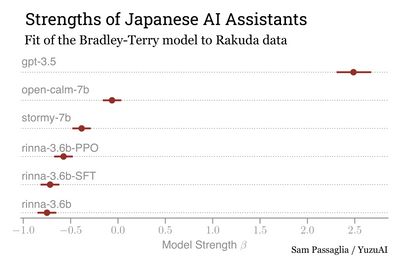
We find that both the overall win-rates and the Bradley-Terry strengths show the same qualitative features. GPT-3.5 is far and away the best Japanese AI assistant among the models we tested. Among the open models, open-calm takes the lead. This is surprising since open-calm-7b is a base model, not an instruction-tuned Assistant. An instruction-tuned model based on open-calm, stormy-7b, takes the next rung of our ranking.
One of the advantages of the Bradley-Terry approach is that it allows us to quantify how statistically confident we are in our statement that our reviewer (GPT-3.5) prefers open-calm-7b to stormy-7b. By plotting the MCMC samples, we can trace out the posterior distribution for their relative strength. This automatically marginalizes over nuisance parameters like the home-field advantage parameter .
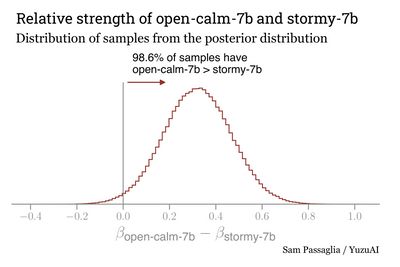
The MCMC results show that open-calm-7b is preferred to stormy-7b at the 98.7% confidence level. This suggests that the instruction dataset used to fine-tune stormy-7b does not produce an assistant more helpful in the eyes of the reviewer.
Here are our full results as a table:
| Rank | Model | Strength | Win Rate | Stronger than the next model at confidence level |
|---|---|---|---|---|
| 1 | GPT-3.5 | 2.487 ± 0.19 | 94% | 100.0% |
| 2 | cyberagent/open-calm-7b | -0.063 ± 0.10 | 52% | 98.6% |
| 3 | izumi-lab/stormy-7b-10ep | -0.384 ± 0.10 | 44% | 90.7% |
| 4 | rinna/japanese-gpt-neox-3.6b-instruction-ppo | -0.575 ± 0.10 | 39% | 83.6% |
| 5 | rinna/japanese-gpt-neox-3.6b-instruction-sft-v2 | -0.717 ± 0.10 | 36% | 59.0% |
| 6 | rinna/japanese-gpt-neox-3.6b | -0.750 ± 0.10 | 35% | N/A |
We also find a home-field advantage parameter . The model strengths and home-field advantage parameter can be used to predict the outcome of any matchup between these models by using the Bradley-Terry probability formula in the previous section.
Parting words
We hope that the Rakuda benchmark and leaderboard will stimulate the development of better and more useful open-source LLMs for Japanese. If you have any model you’d like to add to the leaderboard, or any ideas for how to improve Rakuda, please open an issue on the github repository or contact me directly on Twitter @SamPassaglia or on the YuzuAI discord. As we add models, we will continuously update the main benchmark page.